Converting PDF containing outline text to InDesign
Summary
Recovering content from a PDF file is never a straight forward process. PDF files can be created by any different software and there is no uniformity in the created PDFs. As an example, a InDesign generated PDF is not the same as a Canva generated PDF. Then there are PDF files that only contain scanned data. Finally, there are PDF files created digitally, but, the text are outlined. This article specifically addresses how to convert the contents of PDF files wherein the text are outlined.
Introduction
When text is outlined, the text is converted to a series of vector paths. Thus, the original text is lost. When a PDF is created wherein the text is an outline, converting such a file using PDF2ID directly will yield vector paths in the resulting InDesign file (when text data is expected).
So the question, is how can we recover the text in such a case? There is no single software or solution that allows us to achieve what we want to. Rather, through the usage of 3 distinct pieces of software we can achieve about a 90% success rate when the 3 separate software are used properly . The 3 distinct pieces of software we are going to use are PDF2Assets, Acrobat DC and PDF2ID. Each software plays an important role.
Recovering outlined text as real text from a PDF to Adobe InDesign
We are directly specifying the steps below along with the role each software plays.
1. Convert every page in the PDF file to an image type such as JPEG or PNG.
The very first step is to convert each page of the PDF to a JPEG or PNG using the PDF2Assets application (this seems counter intuitive but it’s the most important first step). PDF2Assets is an application for batch extracting images and graphics assets from PDF files, but it also has the capability to convert every page in a PDF to a JPEG or PNG type. The image below depicts in detail the steps required in –
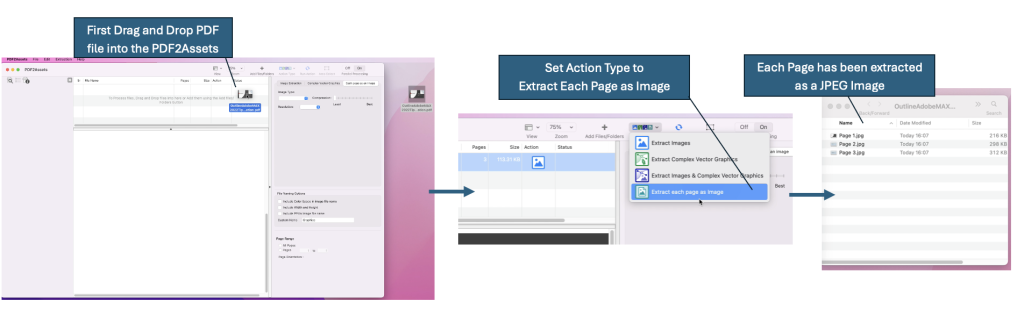
2. Gather the images from PDF2Assets and create a new PDF using Acrobat DC and perform an OCR on it.
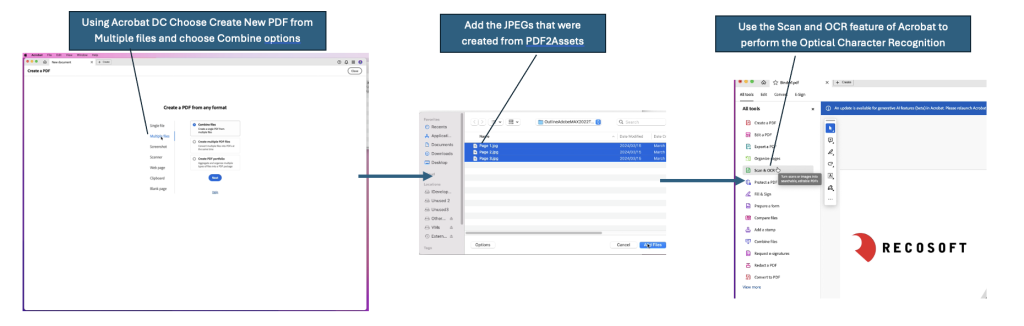
The next step is to create a new PDF file using Acrobat DC by using the JPEG or PNG images that PDF2Assets created from Step #1 above (again, this seems counter-intuitive, but it serves a purpose).
Once we have a PDF that is filled with images, we can use the OCR functionality of Acrobat DC and create a highly accurate PDF containing the text data but make sure to save it! The image below depicts the steps in Acrobat DC to do this –
3. Convert PDF with OCR data to InDesign using PDF2ID
Now that we have a PDF file with the OCR performed on it we can use PDF2ID to convert the PDF file to InDesign type. Once the PDF is converted to InDesign type, we can either hide or delete the images layer as PDF2ID creates a layered InDesign file with the text and images in separate layers!
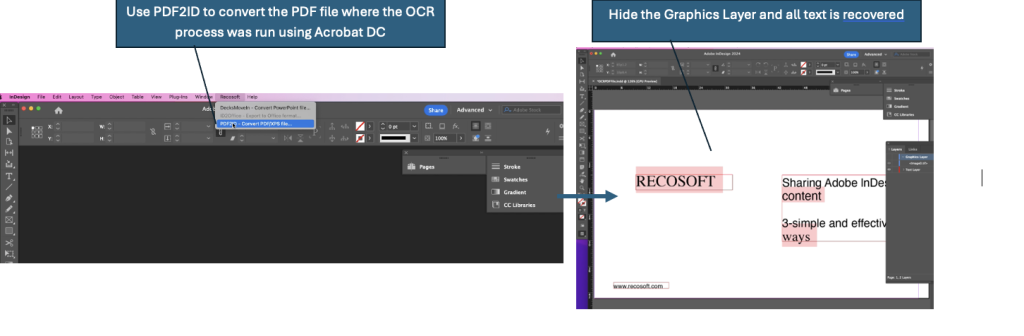
We have successfully been able to convert the PDF file to InDesign with live text!
You can further extract the graphics and images using PDF2ID or even PDF2Assets from the original PDF file that contains outlined text and merge the contents and we have a perfectly working InDesign file.
Conclusion
Summing up, we have now have a solution in place when working with outlined text data in a PDF file. In this case we were able to solve the situation by combining PDF2Assets, Acrobat DC and PDF2ID in an effective and logical way!