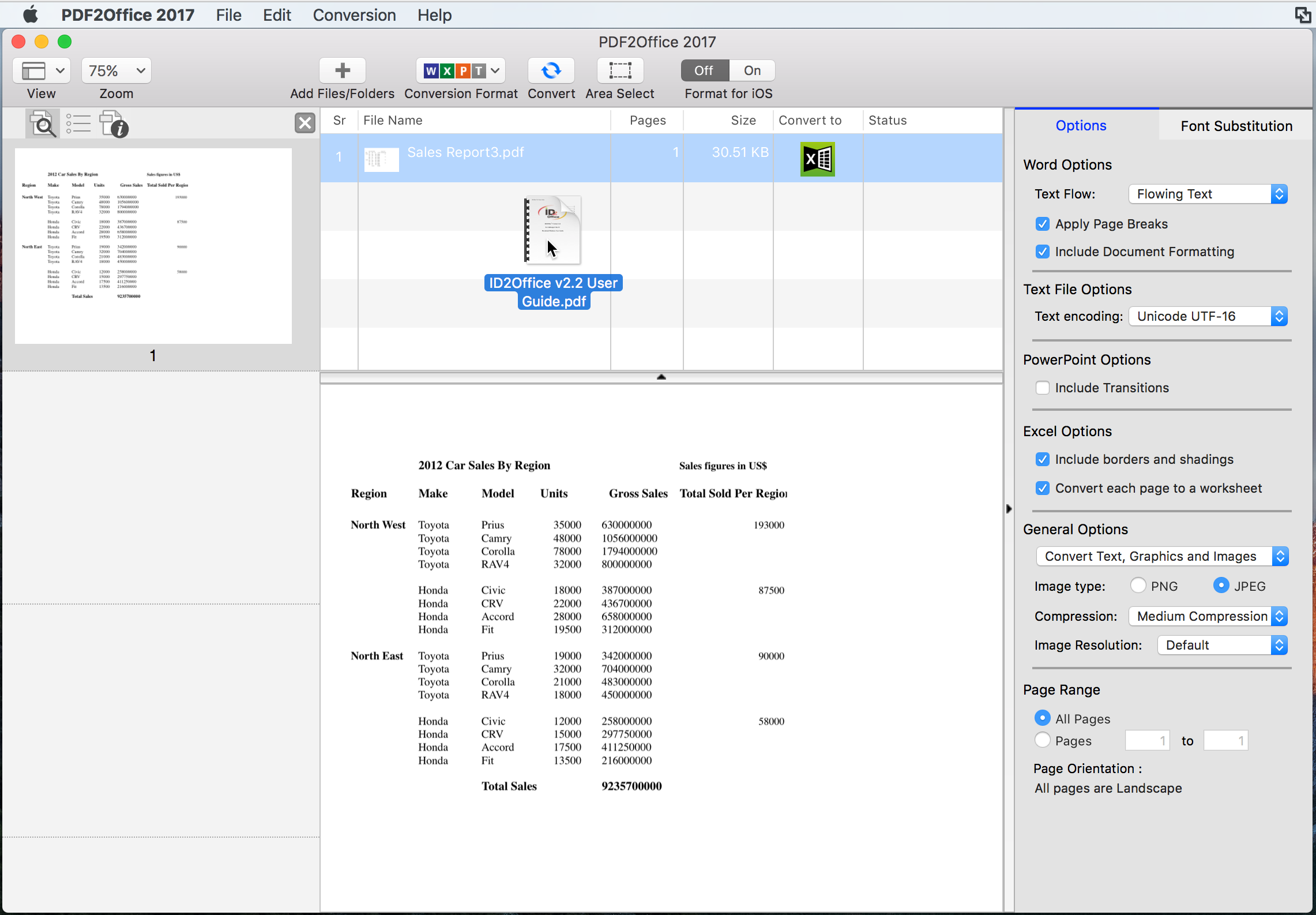
PDF2Office 2017 is a PDF file conversion tool for Microsoft® Excel, Word and PowerPoint®.
Convert PDF to Excel (xls), Convert PDF to PowerPoint (ppt) and Convert PDF to Word (doc).
Convert PDF to Microsoft® Excel, Word and PowerPoint® type
PDF2Office 2017 forms paragraphs, applies styles, regroups independent graphics elements, extracts images; creates tables; processes headers/footers, endnotes/footnotes and columns/sections automatically – without any intervention.
PDF2Office 2017 also provides options for converting or extracting data from a range of pages in a PDF document. You can extract text or images, or convert the entire document to the Microsoft Excel, Word and PowerPoint.
PDF2Office 2017 enables you to recover the data stored in PDF documents – making them available for use by anyone. Since PDF2Office 2017 supports Microsoft Excel, Word and PowerPoint, it is not necessary to acquire and install additional PDF editing software and tools resulting in huge cost savings in both time and expense.